分布式數據庫HBase的數據處理與存儲服務
HBase是Apache Hadoop生態系統中的一個重要組成部分,是一種基于HDFS的分布式、面向列的NoSQL數據庫。它專為處理大規模數據而設計,能夠提供高可靠性、高性能的數據存儲和實時訪問服務。本章將圍繞HBase的數據處理與存儲服務展開介紹,涵蓋其核心概念、數據模型、存儲機制、處理流程以及典型應用場景。
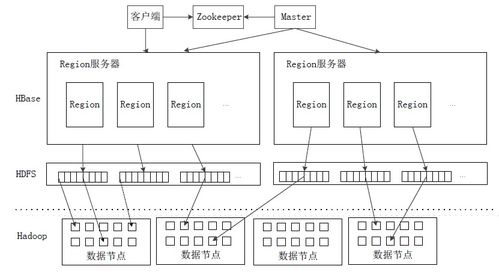
HBase的數據模型以表的形式組織數據,表由行和列組成。每一行通過行鍵(Row Key)唯一標識,列則按列族(Column Family)分組存儲。這種結構支持靈活的數據模式,便于存儲稀疏數據。在存儲方面,HBase利用HDFS實現數據的分布式存儲,并通過Region分區機制將大表水平分割,分布到多個RegionServer上,以實現負載均衡和高可擴展性。
數據處理方面,HBase支持高效的讀寫操作。寫入數據時,HBase先將數據寫入預寫日志(WAL)以確保持久性,然后存儲到內存存儲區(MemStore),當MemStore達到一定閾值后,數據會被刷寫到HDFS上的存儲文件(HFile)中。讀取數據時,HBase通過Bloom過濾器、塊緩存等機制優化查詢性能,能夠快速定位和檢索數據。HBase還支持數據壓縮、版本控制和過期數據清理,以提升存儲效率和數據處理能力。
在分析層面,HBase常與MapReduce、Spark等大數據處理框架集成,支持復雜的數據分析和批量處理任務。例如,用戶可以通過HBase的API或Hive等工具執行查詢和聚合操作。應用方面,HBase廣泛應用于互聯網、物聯網、日志分析、推薦系統等場景,如存儲用戶行為數據、實時監控信息等,以滿足高并發、低延遲的數據訪問需求。
HBase作為一種分布式數據庫,通過其獨特的數據模型和存儲架構,為大數據環境提供了可靠的數據處理和存儲服務。結合其與Hadoop生態的緊密集成,HBase在企業和研究領域發揮著關鍵作用,幫助用戶高效管理海量數據并實現實時分析。
如若轉載,請注明出處:http://m.simaoarabica.com.cn/product/30.html
更新時間:2026-02-24 20:40:32